大语言模型(LLM)已经在多个领域展示出了卓越的性能和巨大的潜力,然而,要想真正发挥出这些模型的强大能力,需要强大的算力基础设施,而芯片是关键。
千呼万唤始出来,第五代英特尔®️ 至强®️ 可扩展处理器,它来了!
若是用一句话来概括它的特点,那就是——AI味道越发得浓厚。
以训练、推理大模型为例:
● 与第四代相比,训练性能提升多达29%,推理性能提升高达42%;
● 与第三代相比,AI训练和推理性能提升高达14倍。

什么概念?
现在若是将不超过200亿参数的模型“投喂”给第五代至强®️ 可扩展处理器,那么时延将低到不超过100毫秒!
也就是说,现在在CPU上跑大模型,着实是更香了。
而这也仅是英特尔在此次发布中的一隅,还包括打破自家“祖制”、被称为四十年来最重大架构转变的酷睿™️ Ultra。
此举亦是将AI的power注入到消费级PC中,用于加速本地的AI推理。
除此之外,具体到英特尔长期在各行各业扎根的AI实战应用,包括数据库、科学计算、生成式AI、机器学习、云服务等等,也随着第五代至强®️ 可扩展处理器的到来,在其内置的如英特尔®️ AMX、英特尔®️ SGX/TDX等其他内置加速器的帮助下,得到了更大的降本增效。
总而言之,纵观英特尔此次整场的发布,AI可谓贯穿始终。
最新英特尔处理器,AI更Power了
我们先来继续深入了解一下第五代至强®️ 可扩展处理器披露的更多细节。
例如在性能优化方面,英特尔将各种参数做了以下提升:
● CPU核心数量增加到64个,单核性能更高,每个内核都具备AI加速功能
● 采用全新I/O技术(CXL、PCIe5),UPI速度提升
● 内存带宽从4800 MT/s提高至5600 MT/s
我们再来纵向,与英特尔前两代产品做个比较,那么性能提升的结果是这样的:
● 与上一代产品相比,相同热设计功耗下平均性能提升21%;与第三代产品比,平均性能提升87%。
● 与上一代产品相比,内存带宽提升高达16%,三级缓存容量提升至近3倍之多。
不难看出,第五代至强®️ 可扩展处理器与“前任们”相比,在规格与性能上着实是有了不小的提升。
但英特尔可不仅仅是披露,而是已经将第五代至强®️ 可扩展处理器用起来,并把实打实的使用效果展示了出来。
例如在大模型的推理方面,京东云便在现场展示了搭载第五代至强®️ 可扩展处理器的新一代自研服务器所呈现的能力——
全部以超过20%的性能提升“姿势”亮相!

具体而言,京东云与上一代自研服务器有了如下的性能提升:
● 整机性能提升达123%;
● AI计算机视觉推理性能提升至138%;
● Llama 2推理性能提升至151%。
这也再一次证明了在五代至强®️ 上搞大模型,是越发得吃香了。
而除了大模型之外,像涉及AI的各种细分领域,如整机算力、内存宽带、视频处理等等,也有同样的实测结果。
这份结果则是来自采用了第五代英特尔® 至强® 可扩展处理器的火山引擎——
其全新升级的第三代弹性计算实例,整机算力提升39%;应用性能最高提升43%。

而且在性能提升的基础上,据火山引擎透露,通过其独有的潮汐资源并池能力,构建了百万核弹性资源池,能够用近似包月的成本提供按量使用体验,上云成本更低了!
这是由于使用内置于第五代至强®️ 可扩展处理器中的加速器时,可将每瓦性能平均提升10倍;在能耗低至105W的同时,也有已针对工作负载优化的高能效SKU。
可以说是实打实的降本增效了。
在云计算和安全性方面,亮出实测体验的同样是来自国内的大厂——阿里云。
在搭载第五代英特尔® 至强® 可扩展处理器及其内置的英特尔® AMX、英特尔® TDX加速引擎后,阿里云打造了“生成式AI模型及数据保护“的创新实践,使第8代ECS实例在安全性和AI性能上都获得了显著提升,且保持实例价格不变,普惠客户。
包括推理性能提高25%、QAT加解密性能提升20%、数据库性能提升25%,以及音视频性能提升15%。

值得一提的是,内置的英特尔®️ SGX/TDX还可以为企业分别提供更强也更易用的应用隔离能力和虚拟机 (VM) 层面的隔离和保密性,为现有应用提供了一条更简便的向可信执行环境迁移的路径。
以及第五代英特尔® 至强® 可扩展处理器在软件和引脚上是与上一代兼容的,还可以大大减少测试和验证工作。
总的来说,第五代至强® 可扩展处理器可谓“诚意满满”、表现非常亮眼,而它背后所透露出来的,正是英特尔在AI领域一直都非常重视落地的态度。
背后是一部AI落地史
事实上,作为服务器/工作端芯片,英特尔® 至强® 可扩展处理器从2017年第一代产品开始就利用英特尔®️ AVX-512技术的矢量运算能力对AI进行加速上的尝试;而2018年在第二代至强®️ 可扩展处理器中导入深度学习加速技术(DL Boost)更是让至强成为“CPU跑AI”的代名词;在之后第三代到第五代至强®️ 可扩展处理器的演进中,从BF16的增添再到英特尔®️ AMX的入驻,可以说英特尔一直在充分利用CPU资源的道路上深耕,以求每一代处理器CPU都能支持各行各业推进AI实战。
起先是在传统行业。
例如第二代至强®️ 就发力智能制造,帮助企业解决海量实时数据处理挑战,提升生产线系统效率,完成“肉眼可见”的产能扩展。
随后,至强® 可扩展处理器开始在大模型界大展身手。
在AlphaFold2掀起的蛋白质折叠预测热潮之中,第三代和第四代至强® 可扩展处理器连续接力,不断优化端到端通量能力。实现比GPU更具性价比的加速方案,直接拉低AI for Science的入场门槛。

这其中就有从第四代开始内置于CPU中,面向深度学习应用推出的创新AI加速引擎——英特尔® AMX的功劳。作为矩阵相关的加速器,它能显著加速基于CPU平台的深度学习推理和训练,提升AI整体性能,对INT8、BF16等低精度数据类型都有着良好的支持。
与此同时,在大模型时代的OCR技术应用,也被第四代至强® 可扩展处理器赋予了新的“灵魂”,准确率飙升、响应延迟更低。
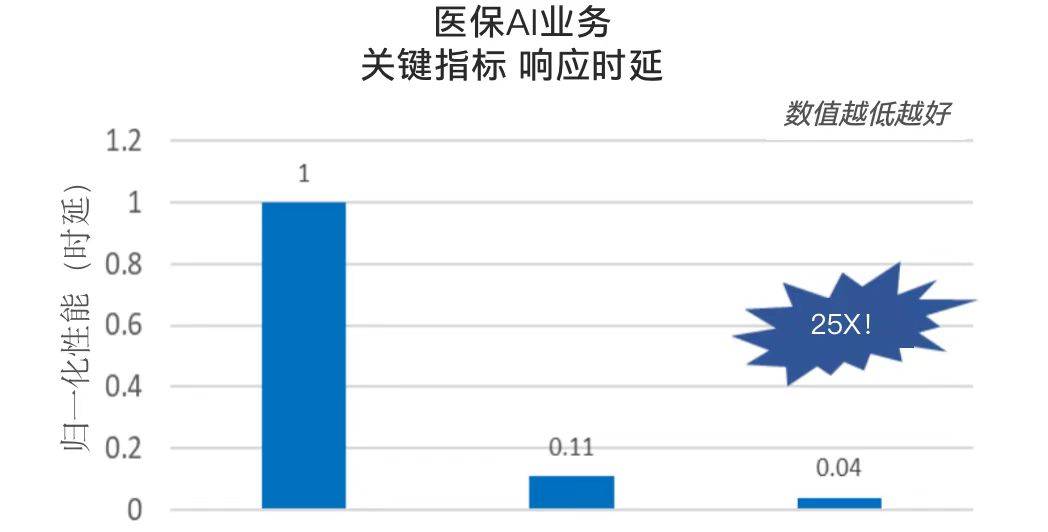
同样,就在不久之前,借助第四代至强®️ 可扩展处理器在NLP上的优化,专攻医疗行业的大语言模型也成功以较低成本在医疗机构部署落地。
在AI技术越来越深入各行各业的大趋势之下,至强® 可扩展处理器让我们看到,它所代表的CPU解法完全能够有所作为、能够让不少AI应用在部署更为广泛、获取更加容易、应用门槛也更低的CPU平台上获得实实在在的落地开花。
第五代至强® 可扩展处理器的发布,则让这个进程更进一步。
当然——
这一成绩的背后,确实是因为大家对“在CPU上跑AI”这件事上有需求,以及它本身也有极其深厚的价值和优势。
先说需求,无论是传统企业推进智能化改造,还是AI for Science、生成式AI等新兴技术的蓬勃发展,都需要强大的算力来驱动。
但大家面临的局势却是:专门的加速芯片供不应求,采购难不说,成本也十分高昂,因此还远远不够普及。
于是一部分人自然将目光投向CPU:
这个现实中最为“触手可及”的硬件,如果直接加以利用,岂不是事半功倍?
这就引出CPU的价值和优势。
就拿当下热门话题生成式AI来说,如果想在生产环境中普及这一能力,就得尽可能地控制成本。
相比训练来说,AI的推理对算力资源需求没有那么夸张,交给CPU完全能够胜任——不仅延迟更低,能效也更高。
像一些行业和业务,推理任务没有那么繁重,选择CPU无疑更具性价比。
此外,利用CPU直接进行部署还能让企业充分利用既有IT基础设施,避免异构平台的部署难题。
以上,我们也就能够理解:在传统架构中引入AI加速,就是CPU在这个时代的新宿命。
而英特尔做的,就是竭尽全力帮大家挖掘、释放其中的价值。
驾驭整个AI管线,且不止CPU
最后,我们再回到今天的主角:第五代英特尔® 至强® 可扩展处理器。

实话说,如果和专门的GPU或AI加速芯片相比,它可能确实还不够炫,但主打亲民、易用(开箱即用,配套的软件和生态越发完善)。
更值得我们注意的是,就算在有专用加速器的场合,CPU无论是从数据预处理,还是模型开发和优化,再到部署和使用,也可以成为AI pipeline的一部分。
其中尤其在数据预处理阶段,它已可以称得上是主角的存在。
无论是以GB还是TB计,甚至更大的数据集,基于至强® 可扩展处理器所打造的服务器,都能通过支持更大内存、减少I/O操作等优势,提供高效的处理和分析,节省AI开发中这一最琐碎耗时任务的时间。
基于以上,我们也不得不感叹,如今英特尔在谈AI时,话题更多样化了。
再加上它在GPU和专门的AI加速芯片上也有布局,“武器库”里的选择也更多了,火力覆盖的能力也更全面了。
毫无疑问,这一切,都指向英特尔全面加速AI的决心。
即用一系列具有性价比的产品组合来快速满足不同行业的AI落地需求。
AI 落地时代开始了,英特尔的机会也来了?

[责任编辑:linlin]
标签:
相关文章










- 1 “网红小吃”柳州螺蛳粉瞄准预制菜产业 全球微资讯
- 2 环球即时看!叙利亚石油业痛失1119亿美元! 叙记者质问:美国还要掠夺多久
- 3 当前最新:南华仪器(300417)6月28日主力资金净卖出91.76万元
- 4 停息挂账后忘记还了会怎样?停息挂账自己怎么去申请?_环球快资讯
- 5 【全球播资讯】三星 Galaxy Watch 5 现在在限时优惠中立减 61 美元
- 6 国有大行公告:7月起清理个人长期不动存折账户 每日速递
- 7 川木是好人还是坏人 川木是谁 时快讯
- 8 鼓励加油的英文单词怎么写_加油的英文_世界简讯
- 9 要闻:805插件桩位偏差怎么用 805插件
- 10 一泰铢兑换多少人民币(2023年6月28日)
- 2018年村主干考试_2018年村干部考公务员试题|环球时讯
- 阿斯顿·马丁也要生产纯电车了!斥资2.32亿美元向Lucid购买技术
- 广骏集团控股(08516.HK)年度净亏损扩大至2730万港元 明日复牌 全球动态
- 降息潮下的银行揽存众生相 | 大行“利率秒降”,腰部银行“贴息坚守”,小银行又该如何留住存款?
- 名单公布!他们是德州新时代好少年!-实时焦点
- 夏季达沃斯论坛与会嘉宾:中国依然是世界经济增长的重要引擎
- 标语口号_关于标语口号概略
- 全球微速讯:教育部发布温馨提示:高校招生录取期间 谨防受骗
- 无锡新国标电动自行车是什么意思?-每日消息
- 漫画|@同学们,这份暑期安全攻略“拍了拍”你|每日时讯
- CPU也可以完美运行大模型 英特尔第五代至强重磅发布
- 华润紫竹药业毓婷携手美柚、大姨妈,双平台联动打造“爱情避修课”
- 以专业换安心,贝壳杭州站万余名考生奔赴“搏学大考”
- 车险与道路安全设施建设关系
- 环滇池侧记|做好服务保障 为参赛选手护航
- 算力共建,智贯东西:2023英特尔算力大会暨东数西算大会隆重举办
- 2023 CCF国际AIOps挑战赛决赛暨“大模型时代的AIOps”研讨会成功举办
- 助力乡村教育——八方锦程向龙岩陈东学校捐赠教学电脑
- 墨水屏行业首款7英寸彩屏!掌阅iReader Color 7 定22日发布
- 喜讯|棕榈股份再获国家高新技术企业认定
- 尊享皇派,守护美好 | 皇派门窗「皇+服务」焕新进行时!
- 眼睛怕疲劳,常喝蓝莓宝,福兰农庄推出蓝莓宝100%NFC蓝莓复合果汁
- 袁亚非:带领三胞集团转型大健康成绩显著
- 瑞安市留学人员和家属联谊会北京分会 成立暨第一次会员代表大会在京 隆重举行
- 领跑行业14年,「孩子王」如何做到超1000家门店,逾8500万会员的?
- 健康方舟young生滋补节2周年庆12月23日-1月1日限时开启,花式演绎滋补养生
- 中国国新华夏之脉首届线下会议重要试点项目启动大会圆满成功
- 重庆画室:美术生在决定校考前,需要避哪些坑?
- 破解“恐针”难题,江西三鑫无针注射器性价比王者重磅上市!
- 国风再现!「Heyone黑玩」热门IP——MIMI潮玩新品发布
- “低调实力派”盘点虬龙科技在电动越野领域走过的十年
- 泰瑞应急数字孪生底座赋能防灾减灾,提升预警监测与应急指挥能力
- 重庆画室:重庆美术生一般去哪里参加寒假培训班?厚德路画室寒假班!
- 消费者需擦亮眼睛看测试,魏牌高山MPV超长续航不容置疑
- 学会科学避险,远离地质灾害
- 姜敏杰:30年专注菜籽油,新兴粮油助推中国油菜产业发展
- 庭院小经济助力乡村大振兴
- 善建成长·总台春晚龙年压岁金上市发布会在京成功举行
- 相约明年!2023粤港澳大湾区服务贸易大会圆满落幕
- 【学术盛宴】大咖云集·精彩纷呈 2023青海省眼病高峰论坛成功举办!